Арсен Яковлев, Григорий Франгуриди
Для правильного тестирования торговых стратегий недостаточно только исторических данных: нужно уметь генерировать псевдоряды котировок. Сделать это позволяют математические модели класса ARFIMA.
После формализации алгоритма возникает вопрос, будет ли построенный на его основе робот приносить прибыль. Чтобы на него ответить, проводится процедура тестирования, которая, как правило, заключается в проторговывании стратегии на одном ряде исторических данных. Если придерживаться правдоподобного мнения о том, что биржевые хроники представляют собой случайные процессы, то становится ясно, почему такое тестирование исключительно ненадежно. Ведь исторический ряд мог бы быть совсем другим, и стратегия на нем принесла бы другую прибыль, имела бы другие характеристики риска и пр.
Судить о каких-либо параметрах стратегий, «живущих» на стохастических (случайных) рядах, можно только с вероятностной точки зрения. Значит, необходимо тестирование стратегии на целом множестве рядов данных с целью получения распределения доходностей (или других интересующих спекулянта характеристик стратегии, являющихся случайными величинами). Так как в действительности нам доступен только один ряд исторических данных по каждому инструменту, чтобы правильно тестировать торговые стратегии, нужно уметь генерировать псевдоряды котировок. Этой цели служит стохастическое моделирование.
Задачи стохастического моделирования
Представим себе стрелка, которому требуется проверить ружье на точность стрельбы. Сколь бы метким ни был стрелок, вряд ли после первого неудачного попадания он забракует оружие. Скорее всего, он совершит серию выстрелов и посмотрит, насколько равномерно и густо сгруппированы пулевые пробоины вокруг центра мишени. Если среднее расстояние от центра мишени окажется небольшим, а «типичное» попадание будет приходиться «в яблочко», то стрелок, безусловно, должен остаться доволен ружьем. Он может посетовать на то, что не может обеспечить точного попадания в 100% случаев, однако ему не придется жаловаться на оружие.
По существу, игроки рынка ценных бумаг, тестирующие торговую стратегию на пригодность в использовании, подобны стрелку, проверяющему оружие на точность. Если стратегия показала хорошую доходность на исторических данных, то это не означает, что так будет и в будущем. Так, первое попадание «в молоко» не должно смутить опытного стрелка. Более приятно, конечно, обратное утверждение. Если стратегия продемонстрировала не слишком впечатляющие результаты на биржевых хрониках, то нет еще достаточных оснований забраковать ее. Подобно разумному стрелку, трейдер должен продолжать тестирование на псевдорядах для получения распределения доходностей стратегии.
Методы выявления распределения доходностей стратегии путем ее исполнения на большом наборе рядов данных относятся к классу так называемых методов Монте-Карло. В силу ограниченности исторической информации для использования методов Монте-Карло необходимо уметь генерировать псевдоряды котировок, прежде подобрав для них правильную модель.
Фиктивные ряды должны быть «похожи» на исторический ряд по инструменту, на котором тестируется стратегия. Определение степени «похожести», «близости» рядов — задача, имеющая множество подходов. Базовая идея состоит в том, чтобы псевдоряды имели сходные с историческим рядом статистические характеристики (персистентность, волатильность, «степень» стационарности и пр.). При этом большую значимость нужно придать схожести тех характеристик, которые реально эксплуатируются тестируемой стратегией. Именно по причине требования «похожести» всех псевдорядов на показательный исторический ряд должна быть отвергнута идея об использовании в процессе тестирования рядов данных по другим (близким) инструментам: хорошо известно, что даже похожие бумаги в статистическом смысле могут вести себя совершенно по-разному.
Помимо получения результатов распределения доходности системы теория случайных процессов предоставляет нам средства для оптимизация ее параметров. Пусть стратегия зависит от параметров, каждый из которых может принимать значений. Тогда проторговываний стратегии на (многомерной) «сетке» параметров позволят нам выбрать такую комбинацию параметров, которая оптимизирует нужную характеристику (например, доходность). Так ли это? Вспомним, что цена есть случайный процесс, а значит, доходность стратегии — случайная величина. Каждой комбинации параметров соответствует лишь одна реализация этой случайной величины, а распределение остается неизвестным. Но, чтобы уверенно судить об оптимальности комбинации параметров, необходимо знать распределение доходностей, а значит, использовать сгенерированные ряды нужно не только для тестирования стратегий, но также и для оптимизации ее параметров.
Для того чтобы построить множество случайных рядов (в процессе тестирования их может использоваться до 100 тыс.), необходимо выбрать форму случайного процесса, реализации которого будут использоваться в тестировании. Мы остановились на процессах класса ARFIMA. Эти модели хорошо исследованы в теории и на практике, относительно доступны и в то же время обладают широкими возможностями. Так, модели ARFIMA позволяют «ухватывать» многие устойчивые статистические закономерности, присущие реальному рынку, такие как длинная память, кластеризация волатильности, негауссовость и тяжесть хвостов распределения (логарифмических) доходностей, информационные послешоки и пр. Чтобы понять, как получить модели для генерации псевдохроник, необходимо окинуть взглядом историю стохастического моделирования в финансах.
Эволюция стохастического подхода
Развитие представлений о процессе, порождающем биржевые хроники (data generating process), происходило по пути «охвата наибольшего числа эмпирических фактов наименьшим количеством формул»1. Даже последние модели финансовой эконометрики допускают спецификацию в несколько строк, однако это не делает их внутренне менее сложными.
Первая попытка описать биржевые данные математически приписывается французскому математику Л. Башелье, который в своей диссертации 1900 года («Математическая теория спекуляций») ввел процесс случайного блуждания:
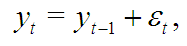
где ![]() — независимые, одинаково распределенные случайные величины с нулевым математическим ожиданием и постоянной дисперсией (отклонением случайной величины от математического ожидания)
— независимые, одинаково распределенные случайные величины с нулевым математическим ожиданием и постоянной дисперсией (отклонением случайной величины от математического ожидания) ![]() .
.
Часто к спецификации модели случайного блуждания добавляют, что приращения ![]() распределены нормально (имеют распределение Гаусса), то есть их плотность имеет такой вид:
распределены нормально (имеют распределение Гаусса), то есть их плотность имеет такой вид:
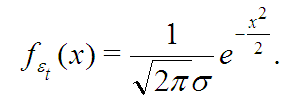
Нормальное распределение выбрано здесь не случайно: оно занимает особое место в теории вероятностей, а именно участвует в так называемой центральной предельной теореме (ЦПТ), которая утверждает, что при некоторых не слишком ограничительных условиях на степень зависимости нормированные суммы одинаково распределенных величин стремятся обрести Гауссов профиль плотности распределения. Иными словами, если на случайную величину одновременно влияет огромное количество независимых факторов, действие каждого из которых пренебрежимо мало по сравнению с совокупным действием остальных, то такая случайная величина будет близка к нормальной. Но именно это в первом приближении и происходит с изменением цены: на нее влияет множество факторов, которые почти невозможно предсказать, а значит, изменение должно быть примерно нормальным.
Итак, считая, что ![]() — цена финансового актива в момент времени t получаем простейшую модель финансового рынка. Заметим, что эта модель, как и почти все последующие, не ставит своей целью объяснить причины движений рынка, а лишь постулирует форму порождающего данные процесса.
— цена финансового актива в момент времени t получаем простейшую модель финансового рынка. Заметим, что эта модель, как и почти все последующие, не ставит своей целью объяснить причины движений рынка, а лишь постулирует форму порождающего данные процесса.
Интересно, что одним из рецензентов диссертации Башелье был великий математик А. Пуанкаре, который разочаровался тем, куда направил свой талант модолой Башелье. Однако Пуанкаре оказался неправ. Сегодня финансовая математика, основателем которой считается Башелье, — развитая ветвь математики, по содержанию и глубине не уступающая геометрии и топологии, в которых проявил себя Пуанкаре.
Основная проблема модели случайного блуждания в том, что ряд может принимать отрицательные значения (независимо от начального условия ![]() ). Башелье сам исправил этот недочет и заменил цены их логарифмами, так что:
). Башелье сам исправил этот недочет и заменил цены их логарифмами, так что:
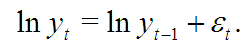
В этом случае при ![]() цены
цены ![]() всегда положительны.
всегда положительны.
Непрерывным аналогом является модель геометрического броуновского движения (geometric brownian motion, GBM), предложенная в середине XX века выдающимся экономистом П. Самуэльсоном (он использовал название «экономическое броуновское движение»). В GBM ![]() цены
цены ![]() цены удовлетворяют следующему стохастическому дифференциальному уравнению:
цены удовлетворяют следующему стохастическому дифференциальному уравнению:
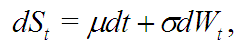
где ![]() — среднее приращений цен (часто полагают
— среднее приращений цен (часто полагают ![]() ),
), ![]() — волатильность (изменчивость) рынка,
— волатильность (изменчивость) рынка, ![]() — стандартное броуновское движение (непрерывный аналог обычного случайного блуждания (см. формула 1)), а d — символ дифференциала.
— стандартное броуновское движение (непрерывный аналог обычного случайного блуждания (см. формула 1)), а d — символ дифференциала.
Стохастическое дифференциальное уравнение, к счастью, решается в явном виде:
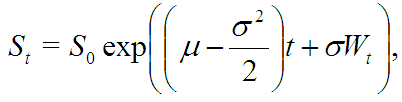
где ![]() — цена в начальной момент времени t=0.
— цена в начальной момент времени t=0.
Отметим, что в знаменитой модели Блэка—Шоулза справедливого ценообразования опционов (Black—Scholes option pricing model) рынок следует именно геометрическому броуновскому движению.
Эффект негауссовости
Парадоксально, но факт: в наши дни, спустя 100 лет (!) после своего появления, модель случайного блуждания в виде часто используется в качестве основной модели рынка. Переписывая как
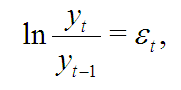
видим, что случайное блуждание логарифмов цен эквивалентно утверждению о нормальном распределении логарифмических доходностей — самой часто встречающейся и самой порочной фразе из статей по спекулятивной торговле.
Почему порочной? Дело в том, что рынок не является нормальным, — этот факт подтвержден сотнями исследований. Гипотезу о нормальном распределении логдоходностей легко проверить, имея данные по котировкам, например, используя критерий Колмогорова—Смирнова или Харке—Бера. Последний использует равенство нулю эксцесса и асимметрии нормального распределения — характеристик вытянутости пика плотности и скошенности плотности относительно математического ожидания соответственно. Но если посмотреть на гистограмму логарифмических доходностей любого ликвидного актива, мы увидим, что пик гистограммы (в нуле) очень высок, а хвосты гистограммы «толстые». Так как гистограмма хорошо приближает плотность распределения, то очевидно, что равенство нулю эксцесса не выполняется на реальном рынке, откуда следует ненормальность распределения логдоходностей.
Факт значимой вытянутости пика (эквивалентно тяжести хвостов) распределения доходностей говорит о том, что экстраординарные (хвостовые) события на рынке происходят чаще, чем то предсказывает нормальное распределение. Рынки падают и растут более резко, а значит, с одной стороны, спекулянт, ориентирующийся на Гауссово поведение, недооценивает риски инвестирования, а с другой — занижает возможную прибыль.
Чтобы учесть эффект негауссовости, было разработано множество моделей, самые заметные из которых — модели класса ARFIMA. Чтобы подготовить читателя к спецификации ARFIMA, заметим, что случайное блуждание может быть компактно переписано в виде:
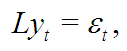
где — так называемый оператор сдвига, действующий по формулам:
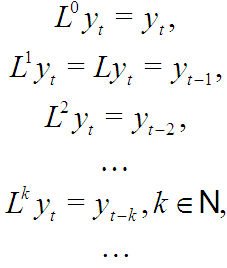
Развивая мысль о том, что текущие цены должны зависеть от предыдущих, можем записать:
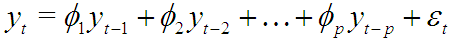
или
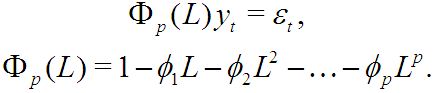
Такое обобщение случайного блуждания называется моделью AR(p), авторегрессии порядка p, — цены в ней образуются регрессией на себя.
В свою очередь, обобщением модели AR(p) является модель ARFIMA(p,d,q):
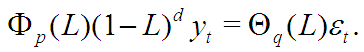
Здесь, как и прежде,
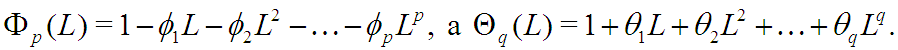
Параметры p,d,q могут принимать любые целые неотрицательные значения. Отметим, что выражение представляет простые последовательные разности ряда ![]() порядка d:
порядка d:
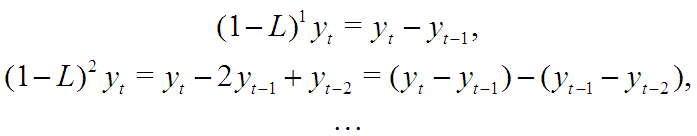
Модели ARFIMA учитывают эффекты информационных послешоков и краткосрочной памяти ряда, а также негауссовости доходностей. Однако, как уже отмечалось, корреляционная структура рынков характеризуется наличием длинной памяти (ряд «помнит», каков он был, очень долго). Чтобы воспроизвести длинную память, недостаточно моделей ARFIMA. Однако для многих стратегий наличие этого эффекта в финансовых временных рядах является принципиальным, а значит, нужно изыскивать модели, которые позволят «ухватить» его. Удивительно, но непосредственное обобщение моделей ARFIMA, класс процессов ARFIMA, уже допускает наличие длинной памяти.

Более того, с помощью моделей ARFIMA можно не только генерировать ряды с длинной памятью, но и легко управлять ею, так как они включают параметр, непосредственно отвечающий за длинную память. Благодаря этому параметру можно генерировать ряды с заранее заданным коэффициентом Херста (то есть персистентностью). Это свойство ARFIMA оказывается чрезвычайно полезным при тестировании трендоследящих и контртрендовых стратегий, так как можно вычислить границы персистентности рядов, на которых стратегия прибыльна, а потом при торговле в режиме реального времени измерять персистентность текущих котировок и вовремя прекращать торговлю при выходе за эти границы или переключаться с трендоследящей на контртрендовую стратегии.
Спецификация процессов ARFIMA и способы их применения в алгоритмической торговле заслуживают отдельной статьи, которая вскоре появится на страницах журнала.
Вы уже сейчас можете начать изучать Видео курс- роботы в TSLab и научиться самому делать любых роботов!
Можно записаться на следующий поток ОнЛайн курса «Создание роботов в TSLab без программирования», информацию по которому можно посмотреть тут->
Также можете научиться программировать роботов на нашем Видео курсе «Роботы для QUIK на языке Lua»
Если же вам не хочется тратить время на обучение, то вы просто можете выбрать уже готовые роботы из тех, что представлены у нас ДЛЯ TSLab, ДЛЯ QUIK, ДЛЯ MT5, ДЛЯ КРИПТОВАЛЮТЫ!
Также можете посмотреть совершенно бесплатные наработки для МТ4, Квика, МТ5. Данный раздел также постоянно пополняется.
Не откладывайте свой шанс заработать на бирже уже сегодня!
























