
Приветствую тебя, друг мой. Если ты читаешь данную статью, то слово TSLab тебе не кажется странным и незнакомым. Ну, а если это так, то ты обязательно пробовал использовать оптимизацию в данной программе. Нередко звучат вопросы: “А почему оптимизация поедает столько памяти?”, “Куда ей столько?”, “А почему у меня оптимизация SМА потребляла максимум 3гб, а данный индикатор потребляет 8гб? Он плохо написан?”. Возможно, и ты задавался таким вопросом. И вот, я решил ответить на все вопросы одной статьей, которая прояснит все детали работы оптимизации и потребления памяти в процессе оной.
Куда девается память?
Именно кэш скриптов будет использоваться при оптимизации. Каждый закэшированный индикатор будет потреблять память в процессе оптимизации. И чем больше вы кэшируете и чем больше баров (свечей) используете в скрипте, тем больше памяти будет занято под кэш скриптов.
Нужно помнить, что при использовании визуального редактора, мы автоматически кэшируем все результаты всех блоков. Следовательно, если у нас есть скрипт вроде изображенного ниже, то, по факту, в кэш будут попадать результаты сразу трех блоков а не одного, как могло подуматься.
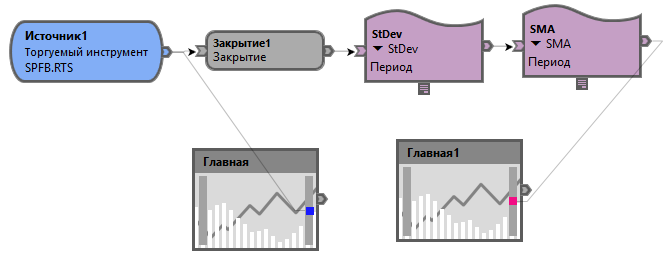
Сначала будет закэширован блок Закрытие, потом StDev, а потом блок SMA. В итоге получает целых 3 результата в кэшэ. Учитывать блок Закрытие мы не будем, так как выход данного блока не изменяется и памяти потреблять будет всегда мало. В общем, чем больше разных блоков в вашем скрипте, тем больше кэша они будут занимать. Зависимость тут вполне линейная. Давайте заглянем в *.cs файл, получающийся после запуска данного скрипта визуального редактора.
// Initialize 'StDev' item
this.StDev_h.Context = context;
this.StDev_h.Period = ((int)(this.StDev_Period.Value));
// Make 'StDev' item data
System.Collections.Generic.IList StDev = context.GetData("StDev", new string[] {
this.StDev_h.Period.ToString(),
"Источник1"
}, delegate {
try {
return this.StDev_h.Execute(Закрытие1);
}
catch (System.ArgumentOutOfRangeException ) {
throw new TSLab.Script.ScriptException("Ошибка при вычислении блока \'StDev\'. Индекс за пределами диапазона.");
}
});
// Initialize 'SMA' item
this.SMA_h.Context = context;
this.SMA_h.Period = ((int)(this.SMA_Period.Value));
// Make 'SMA' item data
System.Collections.Generic.IList SMA = context.GetData("SMA", new string[] {
this.StDev_h.Period.ToString(),
this.SMA_h.Period.ToString(),
"Источник1"
}, delegate {
try {
return this.SMA_h.Execute(StDev);
}
catch (System.ArgumentOutOfRangeException ) {
throw new TSLab.Script.ScriptException("Ошибка при вычислении блока \'SMA\'. Индекс за пределами диапазона.");
}
});
Видим 2 блока кода отвечающих за кэширование данных. Все как я и говорил выше. 2 блока = в 2 раза больше места нужно в кэшэ.
Сколько же памяти нужно?
ОДНО ЧИСЛО
Давайте попробуем посчитать сколько памяти сожрет оптимизация в процессе своей работы. Для этого необходимо вспомнить базовые основы программирования, а именно, сколько памяти потребляет тот или иной тип переменной. Рекомендую почитать статью про типы данных если вы плохо понимаете о чем речь. Итак, кэшировать можно числа double, int и bool величины, это ясно из существующих методов GetData. Чаще всего, нам нужно кэшировать результаты расчетов, а значит это массивы вещественных чисел, то есть массивы double. В некоторых случаях индикатор выдает целые числа (что могло бы позволить сэкономить память), НО в визуальном редакторе все числа переводятся в double и задействовать int получится только в TSLab API. Таким образом придется сосредоточиться только на double, самом распространенном и самом прожорливом варианте. Одно число типа double, хочешь не хочешь, отжимает у нас 8 байт памяти. Одно число int отнимает всего 4 байта памяти, что в 2 раза меньше.
МАССИВ ЧИСЕЛ
С одним числом разобрались, теперь нужно разобраться с массивом чисел. Сколько будет занимать массив чисел? Если не выпендриваться, то можно грубо предположить что массив займет памяти кратно числу ячеек в массиве. Для массива длиной 1000 элементов, памяти нужно 8000 байт.
СПИСОК ЧИСЕЛ
Ладно, с массивом то понятно, а сколько занимает список?? Вот тут более интересно. Внутри списка находится все тот же массив. Для того чтобы иметь возможность добавлять новые элементы в список, массив создается несколько большего размера, так сказать с запасом, поэтому памяти список, почти всегда, занимает больше чем имеет элементов. На сколько больше, не всегда можно сказать, но больше. Иногда это может быть 30% текущей длины. В итоге, список отжимает у нас памяти несправедливо много, и мы даже не может заранее знать сколько.
Вообще, зачем нам список если у нас есть массив? Да вот в том и проблема, что мы не можем знать что нам выдает индикатор на выходе себя. Возможно это будет список, а возможно это будет массив. Все блоки визуального редактора на выходе выдают IList
ПРОБЛЕМА ДЛИННЫХ МАССИВОВ
В языке C#, да и в других языках тоже, есть проблема выделения памяти под очень длинные непрерывные структуры, к которым относятся и массивы. Если нам нужно 100 000 ячеек памяти по 8 байт, то операционная система будет искать кусок памяти ЦЕЛЬНЫЙ и НЕПРЕРЫВНЫЙ. Если у нас сейчас программой уже зарезервировано 500 мб памяти, но нет такого цельного длинного куска, то программа запросит у ОС еще памяти и займет новую память. Чем чаще будет происходить такая ситуация, тем больше будет потреблено памяти, при том что фактически куча памяти будет свободной.
Именно этим объясняется тот факт, что большинство программ со временем начинают потреблять все больше и больше памяти. Мой любимый браузер постепенно переходит планку в 2-3 гигабайта и мне приходится его перезапускать. Такую же процедура приходится делать с программой TSLab с завидной периодичностью.
Итоги
В конце концов, мы приходим к выводу что 1 результат расчета будет занимать памяти в кэшэ = число бар * 8. Если предположить что свечей у нас взято 100 000 штук (что вполне себе реальность), то один результат скушает у нас 8 * 100 000 = 800 000 байт памяти = 0.76 мб памяти.
В кэш будут попадать только уникальные результаты расчета, следовательно, если мы оптимизируем индикатор SMA на периоде от 1 до 300, то будем иметь 299 уникальных результатов и значит оптимизация займет памяти 299 * 0.78 = 227 мб. Не такая внушительная величина, но не всегда все происходит так легко и приятно как с SMA.
Проверка боем
Давайте проверим на реале все описанные выше расчеты. Большой точности у нас не получится, но в пределах допустимой погрешности мы сможем понять на сколько мы были правы или не правы. Для красоты эксперимента возьмем историю в 1 000 000 бар и элементарный скрипт.
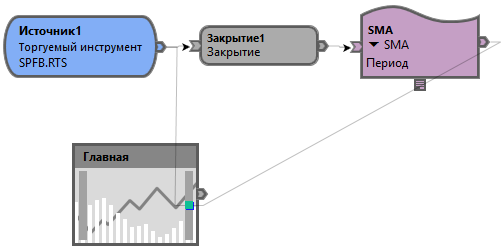
Запустим TSLab с нуля и оценим потребление памяти, после чего запустим оптимизацию на 300 итераций и посмотрим потребление после этого. У меня получилось 580 мб на старте, а по завершению стало.
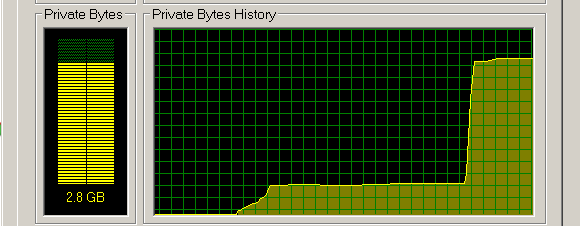
Теперь бессовестно включим математику и посмотрим сколько скушала оптимизация, и вспомним о том что в одном гигабайте всегда 1024 мегабайта, а в одном мегабайте 1024 килобайта, а в килобайте всегда 1024 байта.
Под оптимизацию ушло 2.8 * 1024 = 2867.2 мб. Значит на один уникальный результат ушло 2867.2 / 300 = 9.56 мб. То есть на массив длиной 1 000 000 ячеек ушло 9.56 мб памяти. Значит на одну ячейку ушло 9.56 / 1 000 000 = 10 байт. В итоге на одно число double у нас ушло 10 байт.
Все сходится! Бинго! Небольшая погрешность может быть связана как с тем, что на выходе кубика были списки и памяти было скушано с запасом, так и с тем что TSLab выделил память не только под кэш, но и под другие промежуточные расчета, а так же с тем что закэшировались цены закрытия инструмента (что заняло 10 мб памяти). Просто, нужно быть готовым к тому что памяти будет скушано несколько больше чем получается по нашим грубым расчетам. Но меньше не будет однозначно 🙂
Выводы
Конечное потребление памяти при оптимизации легко рассчитать по следующей формуле:
Память (байт) = ЧислоБар * 8 * ЧислоУникНаборовПараметров
ЧислоБар – сколько бар истории вы подали в скрипт
8 – столько займет одно число double
ЧислоУникНаборовПараметров – сколько уникальных сочетаний параметров в скрипте получается. Это придется рассчитать самому. Далеко не всегда эта цифра равна числу итераций в скрипте. Для двух скользящий с периодом от 1 до 300, число уникальных наборов будет равно всегда 299, при том что число пересчетов будет много больше. И именно за счет кэширования этих самых 299 уникальных результатов будет получен тот самый прирост скорости оптимизации, который получается при помощи использования GetData.
Родион Скуратовский
Вы уже сейчас можете начать изучать Видео курс- роботы в TSLab и научиться самому делать любых роботов!
Можно записаться на следующий поток ОнЛайн курса «Создание роботов в TSLab без программирования», информацию по которому можно посмотреть тут->
Также можете научиться программировать роботов на нашем Видео курсе «Роботы для QUIK на языке Lua»
Если же вам не хочется тратить время на обучение, то вы просто можете выбрать уже готовые роботы из тех, что представлены у нас ДЛЯ TSLab, ДЛЯ QUIK, ДЛЯ MT5, ДЛЯ КРИПТОВАЛЮТЫ!
Также можете посмотреть совершенно бесплатные наработки для МТ4, Квика, МТ5. Данный раздел также постоянно пополняется.
Не откладывайте свой шанс заработать на бирже уже сегодня!
Читайте также:


![Рэй Баррос: Уроки от трейдера, управляющего миллионами]() Рэй Баррос: Уроки от трейдера, управляющего миллионами
Рэй Баррос: Уроки от трейдера, управляющего миллионами![Вторая волна коронавируса. Что будет с мировой экономикой и экономикой России?]() Вторая волна коронавируса. Что будет с мировой экономикой и экономикой России?
Вторая волна коронавируса. Что будет с мировой экономикой и экономикой России?![26 Ноября 2018г. Старт Курса «Создание торговых роботов в TSLab 2.0»]() 26 Ноября 2018г. Старт Курса «Создание торговых роботов в TSLab 2.0»
26 Ноября 2018г. Старт Курса «Создание торговых роботов в TSLab 2.0»
























